



A.I. Text-to-Video: Fun Toy or World Building Engine?
Sora, OpenAI's New Text-to-Video Generator, may Change the World of Architecture, and Even the Architecture of the World

In this Post:
Why Might Sora Be A Much, Much Bigger Deal Than Just Video
Generative Video vs. World Models
Designing the World Game
The Larger Game Afoot
Brother, Could you Spare 7 Trillion Dollars?
Open AI has once again lit the world on fire with another breakthrough in A.I.: its stunning text-to-video generator Sora:

For architects, there's an obvious application: you can make videos of your proposed design ideas now, as opposed to just images. If anyone (architect or not) hasn't seen it yet, you need to check it out if only for the wonder and spectacle of it all - nearly flawless, hi-res 60 second videos of whatever you want, merely from a text prompt. Outside of architectural applications, I'm sure everyone else had the same thought I did: can we bypass Hollywood and make our own movies now? Because if so, I'm definitely making the John Wick / Jason Bourne team up movie that we all deserve.1

Setting my little fantasy projects aside, I think there's more to the iceberg than we're currently seeing.
Why Might Sora be a Much, Much Bigger Deal Than Just Video
It may be tempting to think that this is a logical extension of the image generators with which we're already familiar. Which, it kinda is. It is, after all, assembling pixels in such a fashion that they eventually express something described by a prompt. The thing is, a program must understand much more about the world in order to do that with video, as opposed to images. Simultaneously, there's much more one can learn about the world from video than from looking at images. Learning from words, or learning from images, will teach you a lot about what’s in the world. Learning from video will teach you how the world works.1
Text < Image < Video
By now, we're all probably already familiar with how Large Language Models work: by predicting the next word in a sequence based on statistical probabilities. We feed them huge amounts of written text, and it works out how one might respond to a question or finish a sentence based on which options seem most likely:
And then . . .
LLMs are just working out which words are most likely to come next, and in the process have developed a kind of ‘intelligence’ that we’ll be debating fiercely for a while.
The process is similar for video generation, but instead of generating one word from the next, it must generate the next video frame based on whatever has come before. That requires an understanding of how things move in space, certain kinds of cause & effect, etc. It is unclear (and probably unimportant) whether Sora understands physics the way that a human might. But it has to deploy some kind of physical reasoning in order to render the scene properly.
Consider four stills of video, in sequence:




If asked to predict what the next still is going to look like, you might guess the following:

But it would actually depend on how fast the ball was moving, which would be described by how far apart in time the stills actually were. If they were merely 1 second apart, then 5A would be a pretty good guess. However, if the stills represented individual video frames (at 1/24 second), then the following would be more likely:

One scenario that would likely never occur is this one:

Because it doesn't matter if you've seen every video on YouTube, you likely have never seen a red ball roll off the end of a wooden table and float upwards. You (a human) are able to guess correctly because you have an intuitive understanding of physics. Even if you don’t know all the equations involved in determining what the ball will do, or where it will be, you have a sense of what’s going to happen, based on the motion of the ball.
So even if Sora doesn't understand physics, in the human sense, it has to get to the same answer. This is already being labeled as an 'emergent property' of text-to-video models: they teach themselves a kind of physics naturally, and intuitively, in the process of figuring out which frame to render next in a sequence.

Generative Video vs. World Models
At first glance, Sora and her new superpower may seem redundant. We already have computer systems that understand physics just fine. We (humans) know what the laws of physics are, and we can easily program those into a machine. This would be familiar to most architects in the form of any rendering program, which uses raytracing to figure out how light is going to fall on a 3D object, so that the rendered image looks like what we might expect.
More recently, we've developed a slew of open, 3D environments wherein the laws of physics come included, like Nvidia’s Omniverse. The Omniverse is insanely cool, but for our purposes here, game design engines are more interesting.
Designing the World Game
If you've never used one, you can think of a game design engine as a kind of pre-planned environment for the design of video games. If you're designing a video game, you want the characters to interact with one another, and their environments, in ways that seem real, and adhere to certain laws. If you wanted to program a video game from scratch, you'd have to program all those laws from scratch, starting with the absolute basics: gravity, light, etc. So, game engines like Unreal Engine offer a platform which game designers can build upon. Game designers can then focus on programming the features that are specific to their game.

What's critical about these game engines is that they have to generate new, spontaneous content based on a player’s actions within the game. They can't store every view of every square inch of a video game's universe - the storage requirements would be too large, and the rendering times would be too slow. Instead, they use a system of laws to generate the imagery that becomes necessary as players encounter it and interact with it.
If, within a game, you drop a rock into a pond, it should make a bigger splash. If you drop a larger rock into a pond, it should make a similar splash, but maybe larger, higher, or with more ripples or something. In a free, open game, the game designers don't know ahead of time what a player might through into the pond, so they develop code that will basically take the laws of fluid dynamics and create the splash that's most appropriate to whatever is happening.
So why is it a big deal that Sora can do something that we already have environments to simulate? Because it appears to be doing so on its own, without the assistance of human programmers. Game engines require armies of game designers, programmers, mathematicians and so forth to write the code that governs what kind of splash a particular rock will make. Sora didn't require any such thing. It's merely been working out what kind of splash to render based on watching lots and lots (and lots) of videos of things splashing into things.
We can see a great example of that in one of the videos that OpenAI included in its press release, created with the prompt "Photorealistic closeup video of two pirate ships battling each other as they sail inside a cup of coffee”:

What really grabbed my eye, though, was how the coffee was foaming as the ships sailed around in it. The coffee is foaming like coffee. The video looks realistic (as realistic as it can be, considering the subject) because it comports with our mental intuition about how coffee behaves when it's being agitated and swirled inside a mug. Water, being swirled in a mug, would behave differently. Water, being swirled around in the ocean, would behave differently. I don't know enough about fluid dynamics to tell you exactly why, but I know the rendered video looks right.
That's pretty cool. Sora basically taught itself physics & fluid dynamics, merely by observing millions and millions of hours of video.
With that knowledge, it can anticipate how objects behave in the physical world. That's consistent with what we've come to understand about large models: in learning to do a thing, they end up learning about other things (emergent properties). To understand and succeed at the basic task of 'generate a video based on this prompt' Sora came to learn the things that would be necessary to complete that task. Sora has apparently learned a whole host of emergent properties along its path to understanding the physical world, many of which we humans learned in infancy:
3D consistency - even as the camera angle shifts through tracking shots, the objects and scene elements move consistently through the space and are rendered appropriately.
Long Range Coherence and Object Permanence - even when an object is moved out of the frame, Sora 'remembers' that it is there, and when it re-enters the frame, it's rendered consistently.
Interacting with the world - Sora understands how one object affects another and changes it, as when a man takes a bite out of a burger, the burger now has a persistent bite mark in it.
Simulating Digital Worlds - Sora can simultaneously render a digital world such as Minecraft while directing the player through that same world.

That last one is a curious one to include, as it is surely less impressive than rendering a street scene full of people in Lagos.

The Larger Game Afoot
Why Minecraft? I suspect that it's something like an Easter Egg. OpenAI is tipping its hand to some of its techniques, and some of its future plans. Sora has just arrived, and it's already so good at rendering the physical world, it begs the question as to what was it trained on? And how was it trained so fast?
If Sora can understand how to render a virtual, 3D game like Minecraft, one can deduce that it has seen them before. And such games would be the perfect way to train something like Sora. You could have Sora watch every video on YouTube as a primer. By why stop there? You could then utilize a game engine to complete the training:

One could use a game engine to generate novel scenes and interactions which GPT4 could then turn into prompts for training/testing Sora. Sora would render the video, and the GPT4 (because it has vision now, and can review videos) could review its work, and offer feedback and suggestions.
The loop wouldn’t be circular, though. It could subsequently use Sora's performance to generate even more novel scenes and double down on any areas where Sora is weak or needed practice, essentially creating an infinite loop of video generation, review, and improvement.
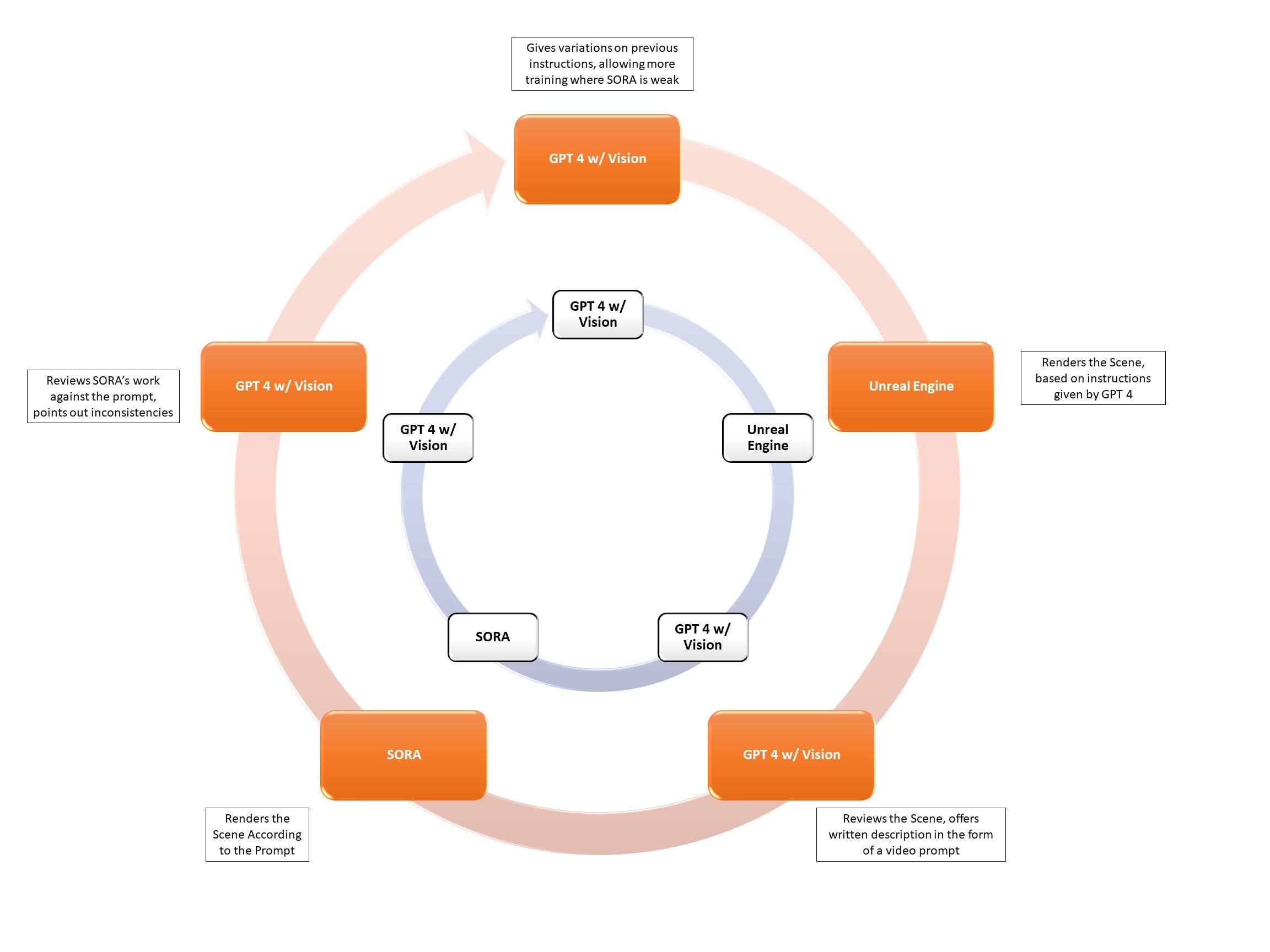
This process could generate/review videos millions of times faster than humans could, and augment Sora’s General World Model with corresponding speed. It suggests that we may be approaching an A.I. that understands the world, not just language. It even pokes at the possibility of AGI depending on how one defines it.
Brother, Could you Spare 7 Trillion Dollars?
All of this would take a massive amount of computing power. Architects know well that even rendering a single image in the correct way can take a really fast computer hours and hours. To generate millions of hours of high quality video in short order would take . . . . well, maybe it would take $7,000,000,000,000.00
That’s the sum that Sam Altman has reportedly been trying to raise for OpenAI’s next round of expansion. That’s equivalent to 10% of global GDP. That seems like a crazy number, until you consider two things:
The massive amount of computing power necessary to bring Sora into the world.
If Sora represents the penultimate step to AGI, there’s no amount of money that governments wouldn’t pay in order to be a part of it.
All told, I think Sora is going to be a really fun, game-changing design tool over the next couple of years. I also think that it portends much more significant, civilization-altering changes in the way we define intelligence, work, design, and all the rest.
If you’re curious, OpenAI expands on this difference in the research paper they dropped alongside Sora entitled 'Video Generation Models as World Simulators.